Plugin e1_ws_API3gen
Popis pluginu e1_ws_API3gen verze 1.0
Modely:
- Processing steps (Processing steps (Request, Extract))
Nepovinný parametr:
- @verboseLog („1“ nebo „true“ = Podrobné logování)
Podpora HTTP-metod v kroku „Request“:
- GET
- POST
- PUT
- PATCH
- DELETE
Podpora dat. formátů v kroku „Extract“:
- JSON
- XML
- (Unknown – zatím bez podpory)
Extrakce dat z konkrétního místa (Path expression):

- V případě formátu JSON se pro extrakci dat používají 2 metody:
- JObject.SelectToken(<Path expression>) – získání jednoho JSON-tokenu.
- Pokud ale výsledkem cesty Path expression (např. „$..objectId“ pro načtení Tickets z HubSpotu) je vícenásobný JSON-token (multiple tokens), použije se metoda JObject.SelectTokens(<Path expression>), která vrátí tabulku se sloupcem „objectId“.
- https://www.newtonsoft.com/json/help/html/SelectToken.htm
- V případě formátu XML se před extrakcí dat nejdříve odstraní případné namespaces (xmlns:) všech atributů XML.
- Jestliže předchozí krok „Request“ vrátí data, která lze načíst do XML dokumentu (XDocument) a je zadané <Path expression>, „Extract“ vrátí filtrovanou kolekci prvků „potomka” pro tento XML document.
- Použitá metoda System.Xml.Linq.XContainer.Descendants(<Path expression>)
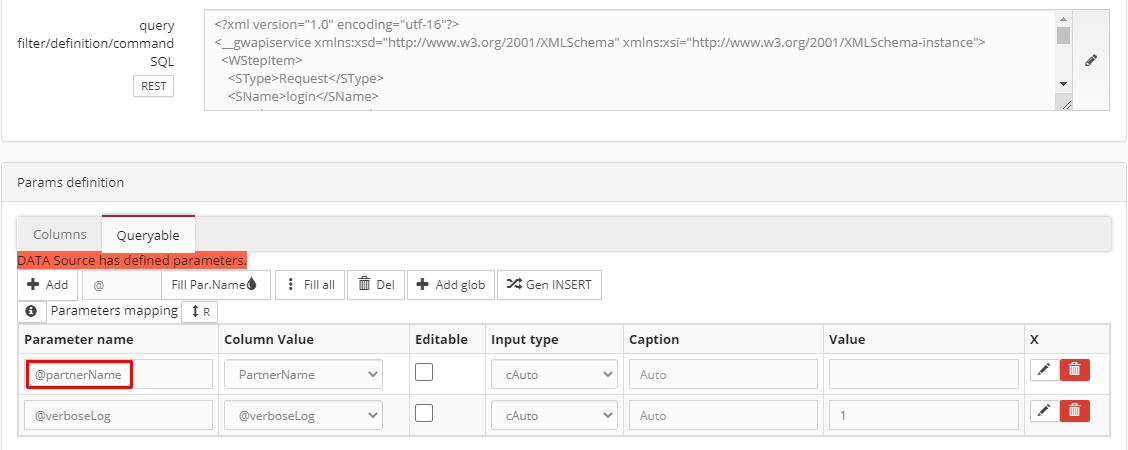
Příklady nastavení definice Zdroje (SQLCommand: REST):
- Příklad načtení Adresáře z API FlexiBee na 1 volání URL:
- 1. krok je typu Request s autorizací v hlavičce dotazu,
- 2. krok je typu Extract, kde výsledná tabulka, obsažená v těle odpovědi ve formátu JSON (Path expression = „winstrom.adresar“), je uložena do interní DB (temp.db3 – tab. „Adresar“)
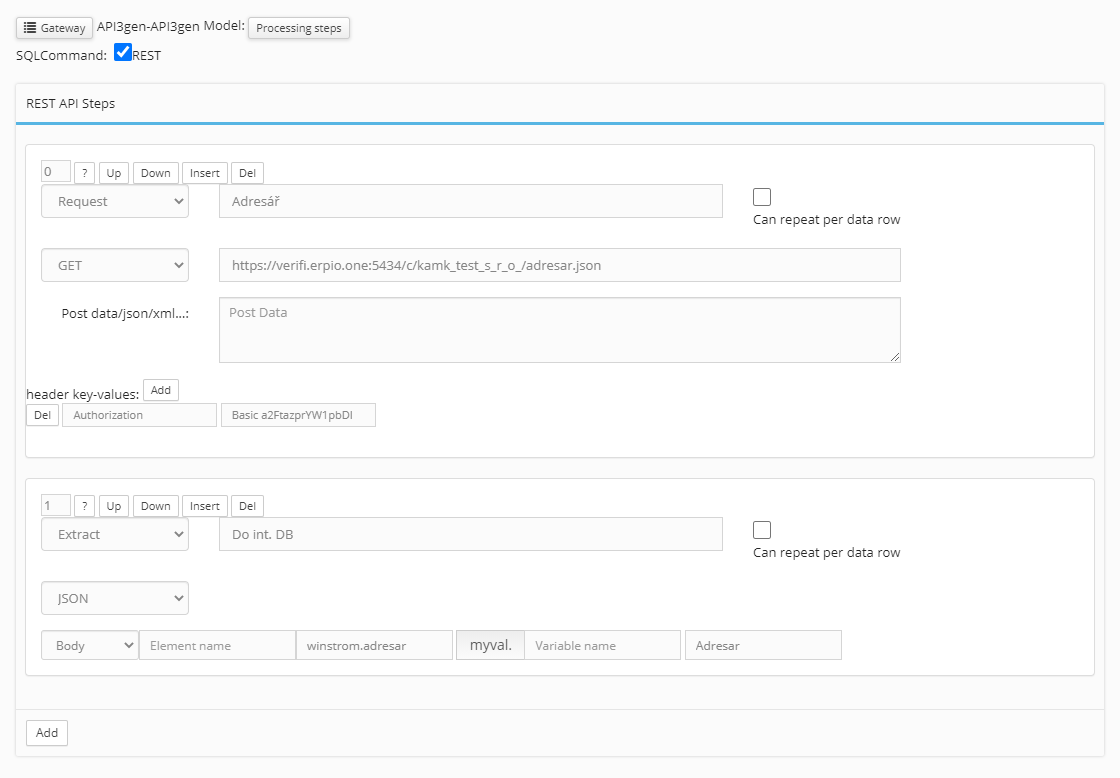
- Příklad načtení seznamu úložišť z M-Files na 2 Requesty, vč. uložení výsledné tabulky do interní DB (temp.db3 – tab. „MyTable“):
- 1. krok je typu Request-POST s autorizací v těle Post data
- 2. krok je typu Extract, kde se výsledný token uloží do proměnné „myval.token“
- Ve 3. kroku se proměnná „myval.token“ použije v hlavičce 2. Requestu
- 4. krok je uložení výsledku 2. Requestu do interní DB (tab. „MF-Vaults“)
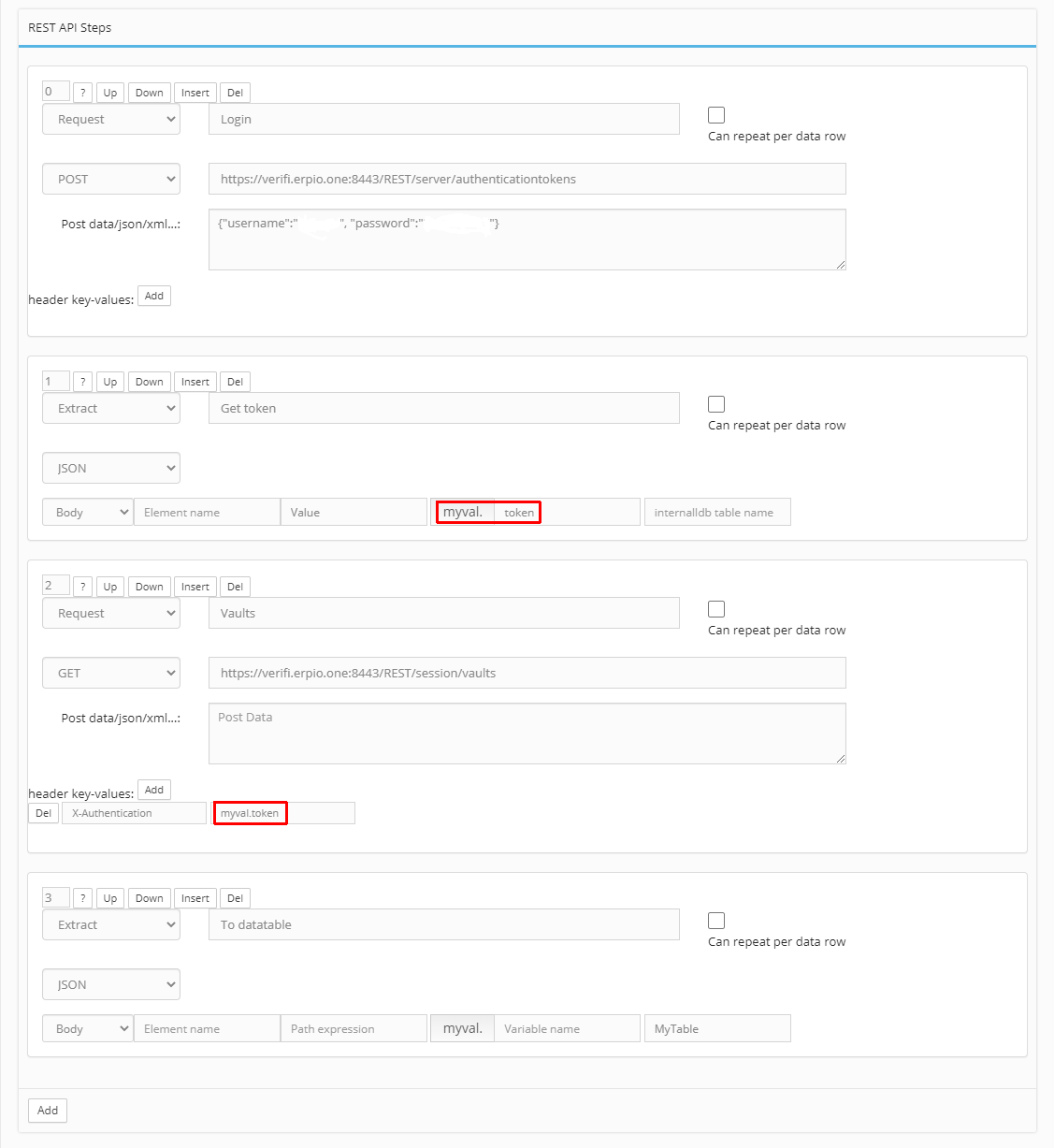
Lze také opakovaně použít načtená data v předchozím kroku „Request“ tak, že následující kroky „Extract“ mohou ukládat data z různých částí/potomků do odpovídajících tabulek int. DB, např.:
- Extract (XML, Body): <Path expression> = „addressbookHeader“, <internalldb table name> = „Pohoda-Adresar_header“
- Extract (XML, Body): <Path expression> = „accountItem“, <internalldb table name> = „Pohoda- Adresar_accountItem“
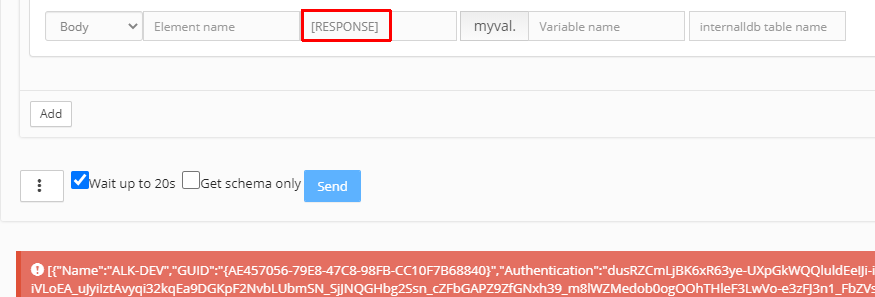
Výpis odpovědi WS (response):
Klíčovým slovem <Path expression> = „[RESPONSE]“ se odpověď vypíše do:
- Logu, pokud je zapnutý parametr @verboseLog
- Tabulky na 1 řádek se sloupcem „RESPONSE“, pokud je vyplněný název tab. <internalldb table name>
- Chybové hlášky v MW, pokud není vyplněný název tab. <internalldb table name> – viz obr.:
Opakování pro řádková data – volba „Can repeat per data row“ (dat. „pumpa“):
Pro každý řádek získané tabulky provede podle mapování sloupců, uvedených v Definici parametrů zdroje, náhradu parametrů (ParName za row[ValName]) v těchto vlastnostech kroků:
- URL
- Post Data
- Pro všechny řádky hlavičky (header key-values)
Dat. pumpu lze spustit i pro skupinu kroků (dvojici/e Request-Response), které se vykonají současně pro 1 řádek zdroj. tabulky (kroky musí mít zatrženou volbu „Can repeat per data row“).
Pokud bude potřeba Request a následný krok zpracovat opakovaně zvlášť, vloží se mezi kroky 1 prázdný krok (bez zatržené volby pro opakované zpracování), který skupinu rozdělí do samostatných zpracovávaných kroků.
Příklad společného zpracování skupiny kroků:
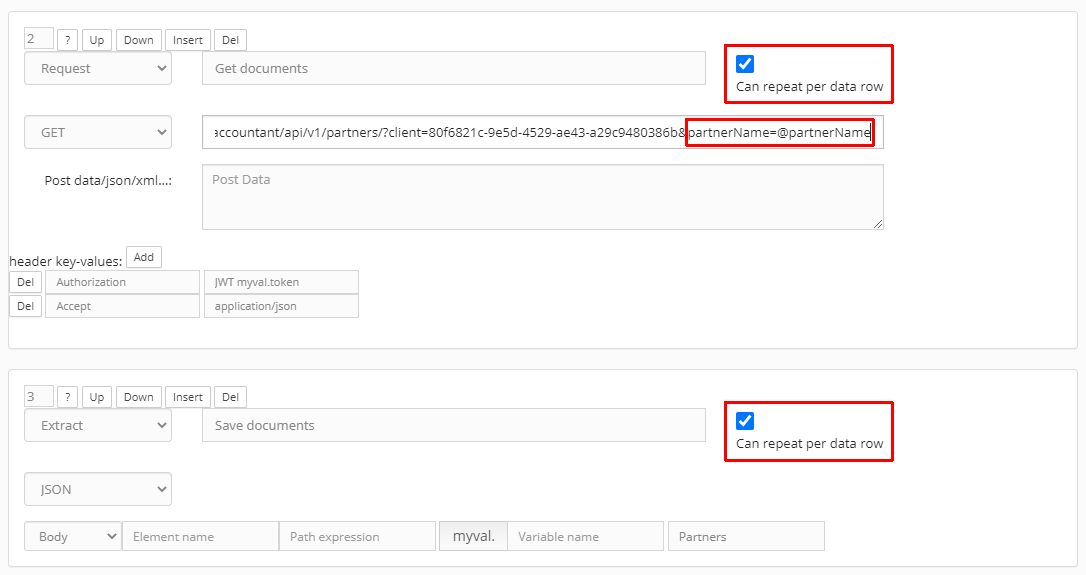
V nastavení MW, v akci typu „Data repeater (pump)“ po nastavení definice REST-příkazu lze nastavit mapování parametrů, např.: